%20(1).avif)




Most teams still fix data problems the hard way because they can only see issues once something’s already broken. By the time a dashboard fails or a model starts spitting out bad results, the damage already exists. Then, teams have to work reactively by tracing the issue back through multiple systems, fixing it upstream, and rerunning pipelines.
This effort wastes hours or even days of development time and, in turn, creates additional rework across teams, slows development velocity, and reduces confidence in the data that downstream systems rely on.
Shift-left data tools fix this process breakdown by moving testing, validation, and data governance to the start of the process. That way, you can catch problems in your code before they ever reach production.
Let’s take a closer look at what shifting left means, why it matters, and the tools that make it possible.
What is shift-left data, and why does it matter?
Shift-left thinking is not as new a methodology as you may think. Engineers have long been using it to preemptively test and review code and perform security checks when building software to avoid downstream breakage.
But data introduces the same set of challenges. When application code changes without clear expectations around the data it produces, breakage will show up later in analytics layers and pipelines. That’s why the same methodology now applies to data. Instead of waiting for broken dashboards or failed models to reveal an issue, shift-left data tools help teams embed validation, testing, and governance directly into the code and pipelines that create and move data. The goal here is to detect schema changes or missing fields at the source, not after the data lands in a warehouse.
“Shift-right” tools, on the other hand, focus on observability by monitoring data after it’s already flowing through pipelines into downstream systems. At that point, all data teams can do is diagnose and troubleshoot failures, which is often too little, too late. But once a breaking change reaches production, the impact can span analytics workflows, reporting layers, and operational systems. Resolving it will require urgent coordination across engineering and data teams, which will mean allocating even more time and money to the project.
A shift-left approach avoids these issues by defining and validating data expectations in application code before deployment. When teams take a preventative approach by enforcing data contracts and lineage upstream, incorrect or incompatible data will never enter production in the first place, and they’ll see fewer compliance risks downstream.
The 10 best shift-left data tools
From code scanning to orchestration and streaming governance, the following 10 tools can help you test, validate, and govern data upstream to support data quality before problems reach production:
Define and validate data early in code
These tools embed testing and validation directly into your codebase or transformation logic so you can catch issues before deployment:
1. Gable
Gable moves data quality upstream by implementing data contracts at the application code level. By integrating directly into development workflows, Gable surfaces breaking schema or semantic changes before code is merged or deployed. This approach allows teams to validate data expectations during build and in the CI/CD pipeline, rather than after downstream systems have already processed the data.
This solution also provides code-level lineage, which maps how data fields propagate across services and pipelines. This gives teams clarity into the downstream impact of changes and enables engineers to reason about data dependencies as part of normal development work.
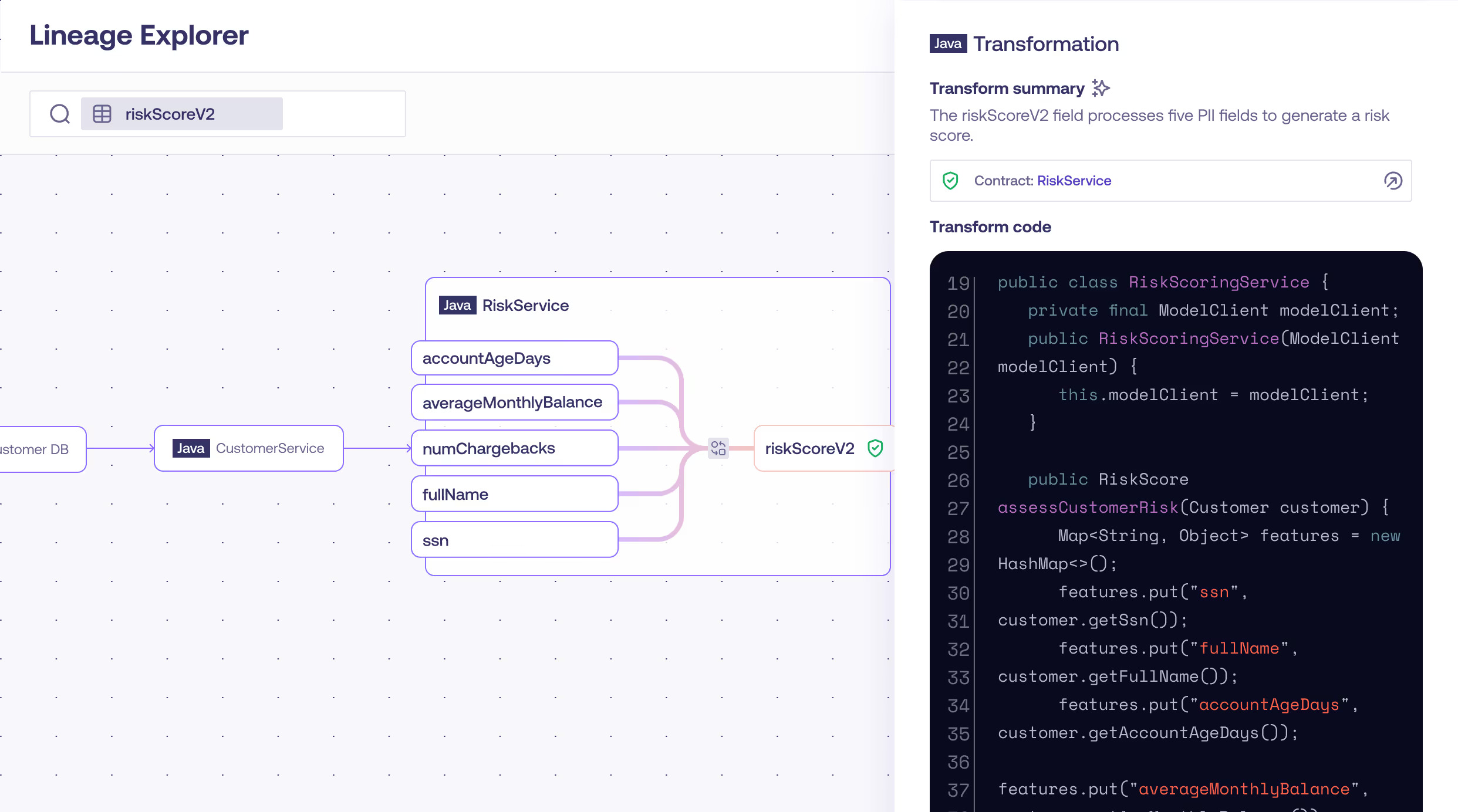
For engineering teams, this reduces rework and on-call incidents related to data breakage. For data and analytics teams, it reinforces trust and stability across the data ecosystem.
Overall, Gable makes data reliability an integrated part of software development rather than a downstream afterthought.
Key features:
- Code scanning: Analyzes application code to show where the code produces, transforms, and passes data between services, making data dependencies explicit. This establishes a clear map of data dependencies without requiring manual documentation.
- Schema change detection: Surfaces structural or semantic changes to data fields during development, allowing teams to see which downstream systems would be affected before merging or deploying the update.
- Data lineage: Traces data from its origin in application code through pipelines, transformations, and analytical outputs. This makes downstream impact visible and helps teams understand how changes propagate.
- CI/CD integration: Validates data contracts and schema expectations automatically in the build and deployment pipeline, ensuring incompatible changes are blocked before they reach production.
- Contract enforcement: Applies versioned, enforceable data expectations directly in code so data that’s produced by services adheres to agreed-upon structure and meaning, preventing breakage across systems.
2. dbt (Core + Cloud)
dbt brings software engineering discipline into data engineering, with version control, modular SQL, and automated testing for transformations. It also helps teams catch logic or model-level errors before they affect reports, which makes analytics code more reliable and maintainable.

However, dbt’s tests run once data already exists, so issues like schema drift or missing fields can still slip through. It’s a powerful tool for improving transformation quality, but it operates further downstream than other shift-left solutions.
Key features:
- Testing framework: Runs data contract and compatibility checks alongside existing unit and integration tests, ensuring validation of data expectations during development.
- Version control: Tracks changes to data contracts and schemas alongside code changes, making evolution explicit and reviewable.
- CI/CD runs: Validates data expectations in the build pipeline, blocking deployments that would introduce breaking changes.
- Dependency tracking: Identifies where code reads, writes, or transforms data so teams can see which services rely on a given field and how changes propagate.
3. Great Expectations
Great Expectations is an open-source Python library that checks whether your data behaves as expected. In it, teams define “expectations,” which are simple rules like “no null values” or “dates must be in range”. Then the system automatically tests them as data flows through. It ensures data meets quality standards before reports or models consume it.
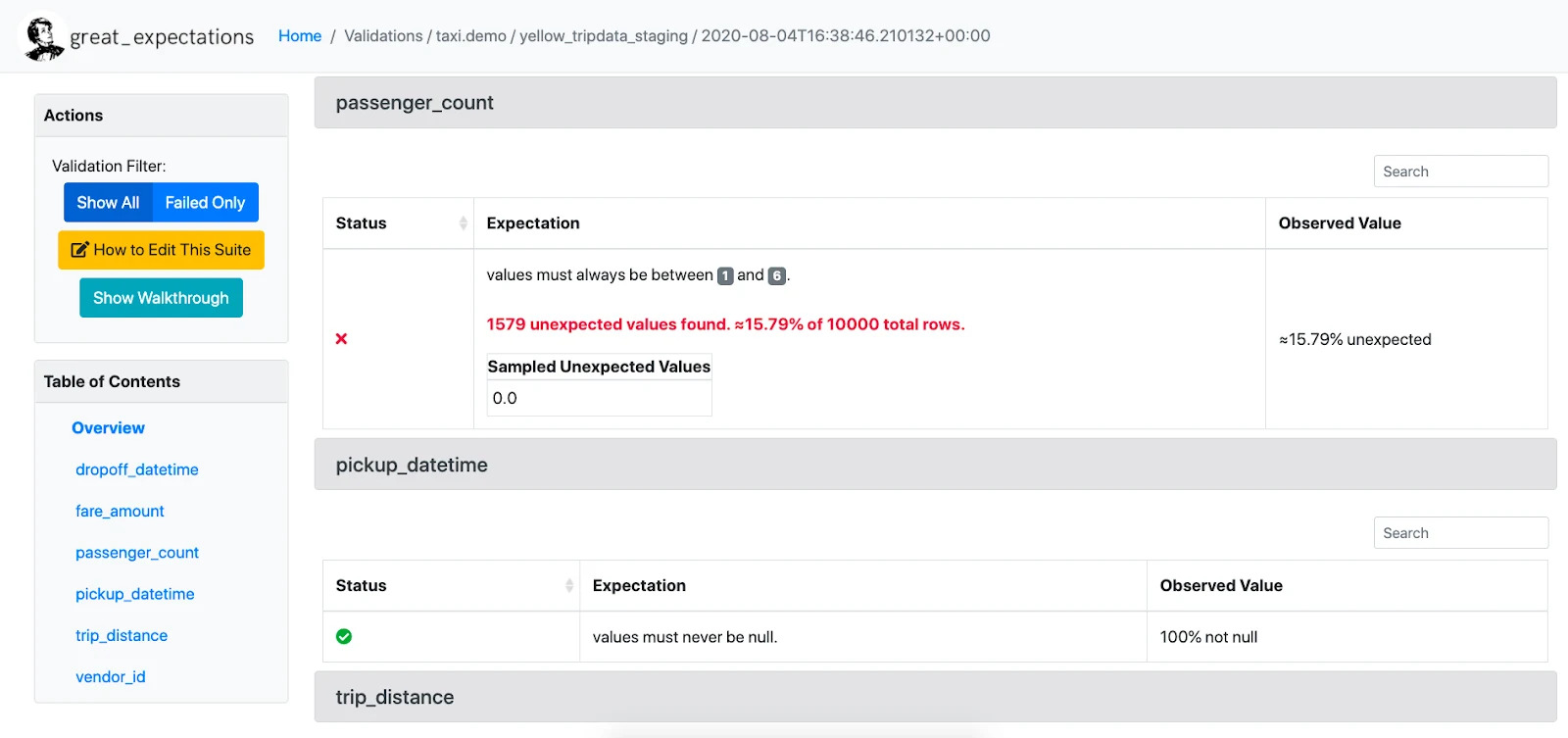
That said, Great Expectations validates data after it is created, not before. So while it’s excellent for enforcing consistency and catching late-stage errors in pipelines, it doesn’t prevent issues at the source. However, when you use it alongside Gable’s data contracts, it becomes part of a more proactive, end-to-end approach to data quality.
Key features:
- Customizable data quality tests: Defines and runs field-level and semantic checks that reflect the expectations of each system or domain, rather than relying on generic rules.
- Automatic data profiling: Analyzes datasets to surface patterns, distributions, and anomalies, giving teams a clear view of how data behaves in practice.
- Integrations with Airflow, Prefect, and dbt: Connects to existing orchestration and transformation workflows so validation and contract checks run as part of normal jobs and releases.
- Automatic documentation generation: Produces up-to-date schema and contract references directly from code, eliminating the need for manual documentation.
Automate and orchestrate data workflows
The following two tools sit in the middle of the data lifecycle and automate how data moves through your pipelines by scheduling, testing, and validating data automatically, which moves checks earlier in the process than traditional post-deployment tools:
4. Airflow
Apache Airflow is one of the most widely used open-source tools for running and managing data ingestion and transformation workloads. It lets teams schedule tasks, define dependencies, and embed data quality checks at every step.
With these controls in place, you can set alerts for failures, retry logic for missed runs, and monitor everything through a clear dashboard.
As a result, Airflow helps teams catch errors as soon as they appear by building testing into workflows.
Key features:
- Automated scheduling and orchestration: Coordinates pipeline execution by defining task order, timing, and dependencies so workflows run consistently without manual intervention.
- Validation hooks for testing data in pipelines: Runs data checks at specific points in the workflow, ensuring data meets expected structure and meaning before the next task executes.
- Built-in retry and recovery options: Automatically retries failed tasks and resumes workflows from the most recent successful step, reducing manual troubleshooting.
- Real-time alerts and monitoring: Surfaces failures and performance issues as they occur, giving teams immediate visibility into pipeline health and stability.
5. Fivetran
Fivetran automates data movement from source systems into a data warehouse and monitors changes to the underlying structures that feed those pipelines. When schemas shift or fields drop unexpectedly, it adapts the pipeline logic so workflows continue running without manual intervention.
With prebuilt connectors and automated updates, Fivetran acts as a “set it and forget it” data platform for seamless integration and early validation.
Key features:
- Hundreds of prebuilt data connectors: Connects to common SaaS apps, databases, and services without custom integration work, allowing pipelines to be set up quickly and consistently.
- Automatic schema drift detection and alerts: Identifies when source structures change and notifies teams immediately so they can review and adjust before these changes affect downstream systems.
- Real-time change data capture: Streams updates as they occur, synchronizing warehouse tables with source systems and reducing data latency.
- Centralized lineage tracking from source to warehouse: Shows how fields move from their origin through every transformation and pipeline stage, making dependencies and downstream impact clear.
Monitor and observe quality continuously
Observability tools monitor your data 24/7 and alert teams when freshness or accuracy issues arise. They also operate further right than development-stage tools like Gable by catching issues as data moves through production, but they’re still key companions to true shift-left prevention.
The following platforms operate in this way to track data quality, freshness, and reliability at scale:
6. Soda
Soda is an open-source data observability tool that helps teams monitor data quality directly from their pipelines.

It uses simple SQL-based tests to check for missing, stale, or incorrect data before it reaches reports or models. And because it integrates with lots of the orchestration and transformation workflows teams already use, they can add data quality checks without introducing new operational overhead.
Overall, Soda’s flexibility makes it ideal for smaller data teams or anyone who’s getting started with shift-left observability.
Key features:
- SQL-based rule creation for data quality tests: Lets teams define checks using familiar query logic, making it straightforward to express expectations about structure, ranges, and relationships in the data.
- Automated anomaly alerts: Surfaces unexpected changes in data values, volume, or patterns as they occur, so you can investigate before these changes disrupt downstream workflows.
- Integration with existing orchestration and transformation workflows: Fits into the pipelines teams already run, allowing data validation to happen as part of scheduled jobs and model updates rather than as a separate process.
- Lightweight setup and fast deployment for modern data stacks: Installs with minimal configuration and relies on existing pipeline components, reducing maintenance overhead and time-to-adoption.
7. Elementary
Elementary brings data observability directly into dbt, making it a natural fit for teams already using modern analytics workflows.

It tracks data tests, schema changes, and freshness checks directly in the pipelines where transformations happen, so validation occurs at the point where data is created and modified. This embeds data quality in the development workflow rather than treating it as a separate, downstream process.
It also generates clear reports and alerts that show exactly where a failure originated, allowing developers to resolve issues without tracing through multiple pipeline stages or downstream systems.
Plus, the tool is open source and easy to install, making adoption straightforward without adding operational overhead.
Key features:
- dbt-native observability and test tracking: Surfaces test results and model health directly in dbt workflows, so teams can see how changes affect data during development.
- Automated alerts for data test failures: Notifies developers as soon as a test fails, pointing them to the exact model and transformation that introduced the issue.
- Schema and freshness monitoring in development: Checks that fields, structures, and update intervals match expectations before data moves downstream.
- Simple open-source setup with clear reporting: Installs quickly and produces readable outputs, making it easy to understand where issues originate and how to resolve them.
Stream and govern data in motion
Streaming tools monitor and validate data in real time, catching issues the moment they occur. They operate between development-time validation and production observability by checking data in motion rather than only before it’s creation or after it’s already downstream.
If you need real-time validation, here’s a popular choice:
8. Confluent (Apache Kafka)
Confluent runs on Apache Kafka to handle high-speed data processing and apply governance controls across streaming pipelines. It also validates message schemas and tracks lineage as data flows between systems, reducing the lag between when issues happen and when you find them.

For event-driven or real-time pipelines, this kind of “in-flight” validation keeps everything accurate and compliant.
Key features:
- Real-time schema validation: Checks each event against the expected field structure as it streams, preventing malformed records from entering downstream systems.
- Lineage tracking: Traces how each field moves across topics and services, showing the origin of the data and the transformation it takes while in motion.
- Stream processing: Applies transformations, filters, and business logic directly to event streams to shape data before it reaches storage or consumption layers.
- CI/CD testing: Runs validation checks on streaming pipelines during builds and deployments, catching breaking changes before they reach production.
- Low-latency delivery: Moves events through the system with minimal delay, enabling near real-time consumption and reducing data freshness gaps.
Govern and contextualize data flows
Governance tools live at the far right of the lifecycle, giving you a full picture of how data moves, who owns it, and how to use it. While they operate later in the process, they’re still vital to a shift-left strategy because they turn early visibility from data contract tools like Gable into ongoing accountability and control. Here are a few centralized governance platforms that will help you do just that:
9. Atlan
Atlan gives teams a shared workspace for data management where you can understand, track, and govern your data. It also combines technical lineage with business context to show not just where data lives, but also who uses it and why it matters.
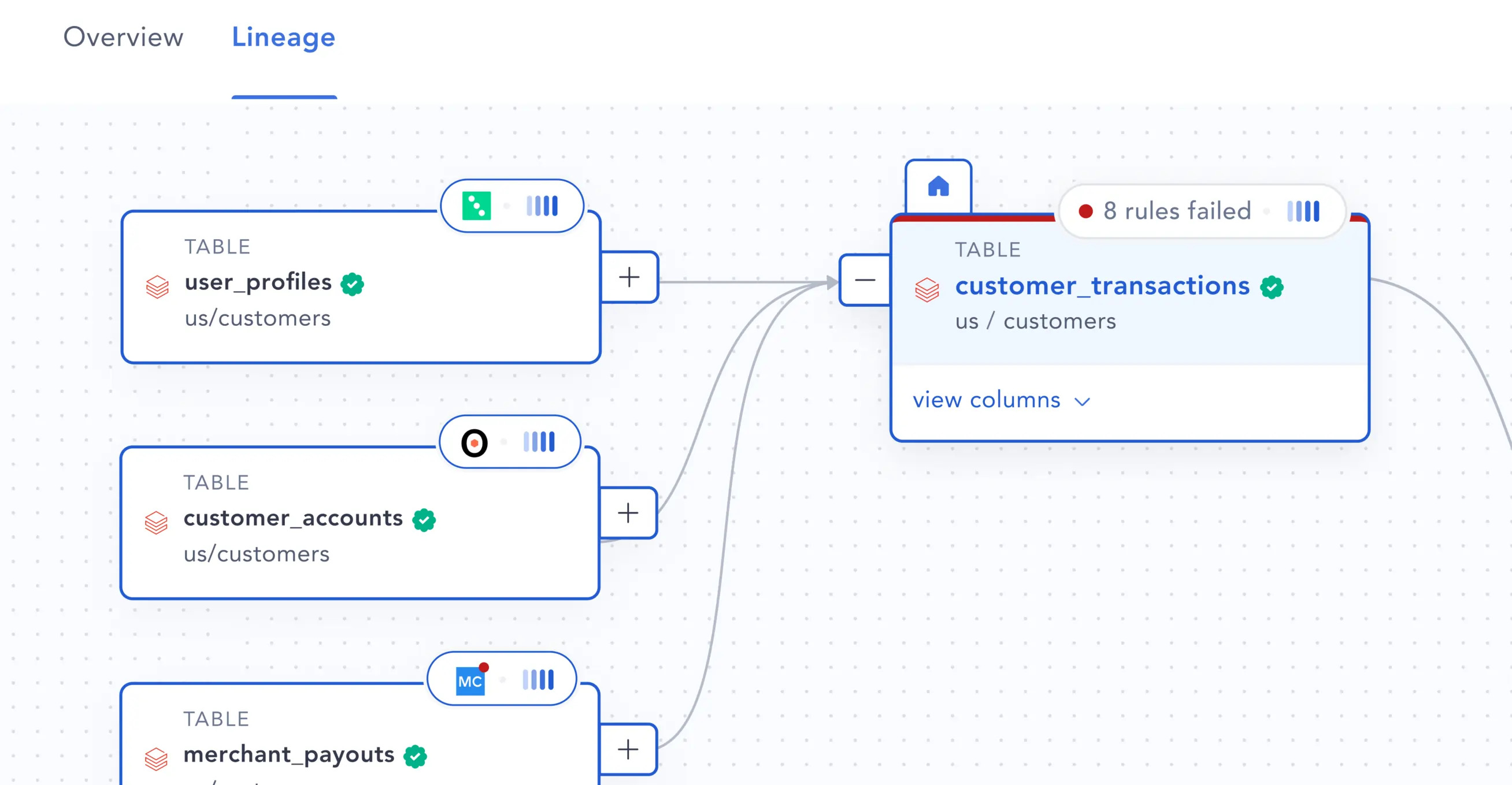
With Atlan, engineers and analysts can easily find, document, and collaborate on datasets in a single shared space, turning governance into a practical, everyday part of their workflow. And when you use Atlan alongside tools like Gable, it helps you translate code-level visibility into clear, organization-wide understanding.
Key features:
- Automated metadata and lineage tracking
- Centralized data catalog and search
- Collaboration tools for ownership and documentation
- Policy and access control management
10. Census
Census is a reverse extract, transform, load (ETL) platform that makes clean, verified data useful beyond the warehouse. It does so by syncing trusted datasets into tools like CRM platforms, marketing platforms, and support systems. That way, every team can work from the same reliable information.
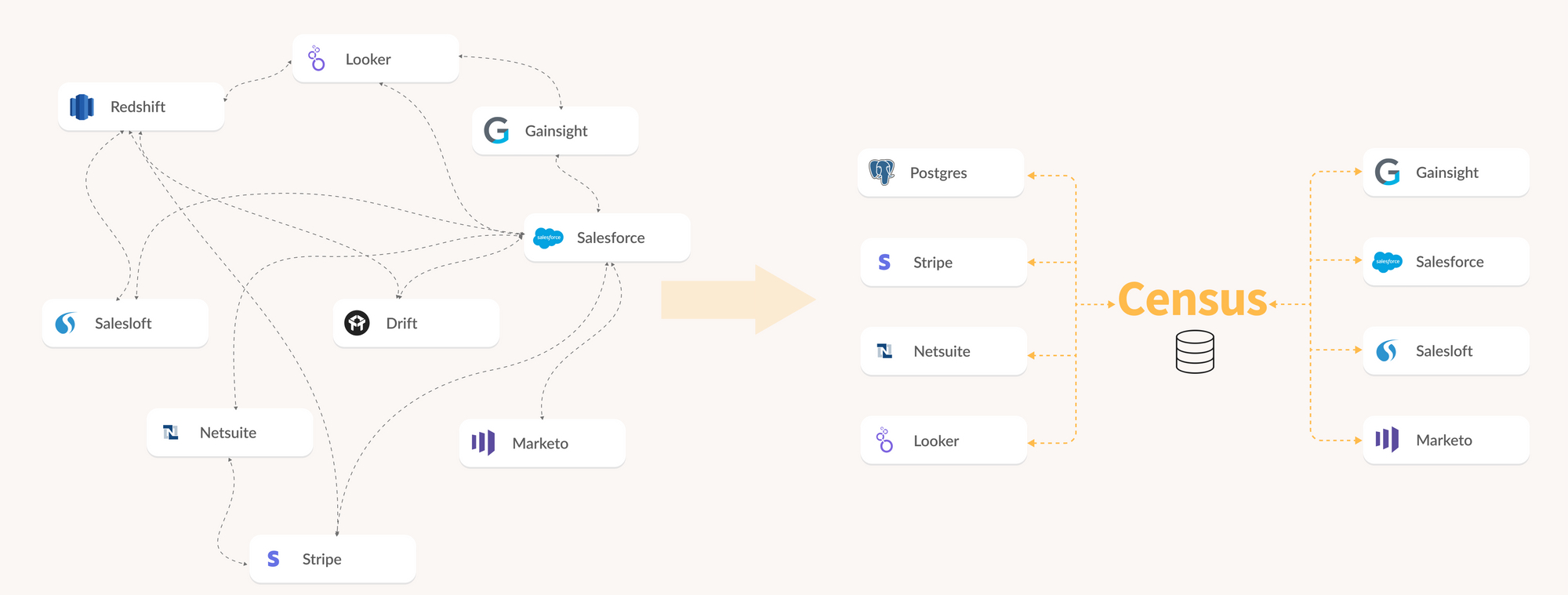
And because it connects directly to modeled and tested data in dbt, Census can help you extend shift-left principles into daily business operations by turning accurate data into real-time action.
Key features:
- Prebuilt connectors to hundreds of business apps and data providers: Connects to common SaaS applications and data sources without writing custom integration code. This reduces setup time and keeps pipelines consistent across sources.
- Automated data syncs and transformation logic: Updates data on a scheduled or continuous basis and applies transformation steps during the sync. This keeps downstream tables aligned with the latest source changes.
- Integration with dbt models for tested data: Aligns sync outputs with dbt models so downstream tables inherit the same tested transformation logic, ensuring consistency between development and production environments.
- Real-time monitoring and alerting for failed syncs: Surfaces sync failures, delays, or schema mismatches as they occur and points teams directly to the cause. This shortens investigation time and prevents downstream breakage.
Key features to look for in shift-left data software
When evaluating shift-left data tools, look for systems that embed reliability into development, not ones that bolt it on afterward. This approach builds consistency into the data lifecycle, making reliability an inherent property of the system rather than something you enforce later through monitoring.
Here are some more specific features you should look for when picking shift-left data software that delivers on prevention:
- CI/CD integration: In a shift-left system, data validation occurs during builds and merges within the CI/CD pipeline. A strong shift-left tool automates these checks so that breaking changes surface before deployment, without requiring manual review.
- Developer-first UX: A strong user experience allows engineers to run tests right where they write code: in their IDE or Git repo. This makes it easier for them to automate data quality without having to juggle another tool or dashboard.
- Data contracts, schema validation, and lineage mapping: Modern shift-left tools use these features together to set clear expectations between data producers and consumers, prevent schema drift, and track how changes move through your pipelines before they break production systems.
- Automation and real-time alerts: Teams need instant feedback when data issues appear, whether that’s during development or after release. The best tools surface schema drift or contract breaks in real time and alert teams early enough to prevent bad data from spreading downstream.
- APIs and ecosystem compatibility: A good shift-left data tool plugs into your existing pipelines without forcing architectural workarounds.
- Governance and auditability: Effective shift-left systems provide traceability for how data changes over time. Built-in change logs and ownership tracking make it clear who modified data, when, and why, which supports compliance and oversight.
If you’re ready to shift left, a practical starting point is the application code layer, because that's where changes ripple downstream.
Shift left and stay ahead: Building reliable data from day one
Shifting left changes data reliability from a downstream concern to part of daily development. When engineers define and validate data expectations in code, issues surface at the moment of change, not after pipelines break. This reduces the time teams spend debugging unexpected failures across services. Instead of reacting to incidents, engineers can ship changes with clearer insight into downstream impact.
Gable supports this workflow by enforcing data contracts in code and mapping how data flows between services. That way, engineers will have the context they need while they build.
If shifting left feels like the right approach for your team, request a demo today to see Gable’s data contracts in practice.

Gable
April 27, 2026

.avif)
.avif)