%20(1).avif)




In modern organizations, data is rarely in short supply, but trust in that data often is. This is the central tension facing today’s data leaders. While organizations rely on data for every mission-critical decision, customer experience, and machine learning model, the frameworks used to validate that data are often lagging years behind the software that creates it.
Effective data validation is a prerequisite for scalable governance and reliable data contracts. However, the industry tends to treat validation as a post-hoc task. It is something that happens in the warehouse after the data has already left its source, potentially breaking several systems along the way. This delay creates a persistent gap between the software engineers who generate data and the data teams who consume it.

To build truly resilient systems, organizations must shift their perspective on what validation means and exactly where it should occur.
Defining data validation in a modern context
Data validation is the process of confirming that data is correct and complete before and as it propagates, starting at the point of creation. It keeps data consistent across systems and aligned with expected constraints, format checks, and business rules. At its core, validation answers the question of whether you can trust data to behave as expected. Historically, this concept was associated with isolated tools like Excel spreadsheet rules or database input fields that require significant manual oversight.
Today, data is generated by application code, transformed through complex pipelines, shared via APIs, and stored in warehouses. Because of this complexity, modern data validation can’t be about fixing bad data after problems arise. Instead, it must prevent invalid data from entering the system and causing it to break in the first place. To achieve this, you need to ensure that data behaves predictably across systems, even as those systems evolve.
Why data validation is critical for enterprise stability
As systems scale and distribute, the cost of invalid data grows with them. A single mismatch or broken assumption can silently move through a data pipeline and eventually corrupt high-stakes decision-making.
This risk makes robust validation critical across several core areas:
- Data reliability and system stability: Prevents mismatches from cascading across pipelines and downstream systems.
- Security and compliance: Enforces data governance policies and supports regulatory compliance.
- Engineering productivity: Reduces time spent on manual checks and reactive debugging.
- AI and machine learning performance: Ensures models rely on consistent, high-quality data.
- Business decision-making and trust: Enables teams to act confidently on reliable data.
Common data validation techniques
Data practitioners typically divide validation techniques into several core categories based on the depth and structure of the check.
Schema validation
The core of structural validation involves checking the basic architecture of a data object. This includes verifying that all mandatory fields are present and ensuring fields match expected data types. It also involves confirming that complex nested structures follow internal rules.
Schema validation is vital for API development, event schemas in distributed systems, and database ingestion.
For example, an event must contain required fields like user_id as a string and a timestamp in ISO 8601 formatting. Failure to meet these constraints makes the data invalid and subject to rejection.
Constraint validation
Constraint validation checks values against defined ranges, enumerations, or uniqueness rules. These checks often encode specific business logic. Examples include ensuring that product prices are never negative or that status values remain within a predefined set.
These rules serve as the primary guardrails for data entry, whether the input is human-generated or produced by a secondary system.
Semantic validation
Semantic validation is a deeper form of validation that ensures data is logically sound within a business context.
It involves several complex layers:
- Cross-field consistency: Checking the relationships between different data fields to confirm they make sense together.
- Referential integrity: Ensuring that data accurately references valid entries elsewhere, such as foreign key constraints in a database.
- Historical and temporal checks: Validating new data against past context or specific time constraints to prevent logical errors.
Implementing these checks is imperative to verify data trust and enable sound decision-making within a coherent data ecosystem.
The challenges of traditional validation models
Many organizations struggle with data validation because they can’t see how engineers produce and change data in application code. This lack of visibility means teams cannot validate what they cannot see. While a data catalog might list what data exists, it often lacks the "how" for manipulating data within application logic.

Fragmentation further complicates enforcement. Validation logic often scatters across the toolchain. It might exist on the frontend, at the API level, or as database constraints. This makes a unified view nearly impossible, leading to inconsistency or duplicated effort. Further, constant changes to the codebase propagate to consumers, invalidating their rules without a clear way to map dependencies.
The most significant challenge is the prevalence of reactive validation. Waiting for data to fail or break a system before dedicating resources to investigate and correct it is profoundly costly. It erodes trust and forces data engineers into a cycle of firefighting rather than strategic work.
Future-proofing systems through strategic data initiative budgets
Solid budgeting is essential for implementing data initiatives that support long-term validation efforts. Data leaders must reframe these budgets as strategic investments rather than problematic cost centers.
When budgeting for validation and data quality, leaders should consider five instrumental components:
- Infrastructure and storage: This covers the physical and virtual environments used to store and process data for the initiative. Pricing typically ranges from $1 to $12 per TB. For example, archival tiers like Amazon S3 Glacier Deep Archive can cost around $1 per TB per month, while frequently accessed storage and compute-intensive workloads cost significantly more.
- Tools and licensing: This component includes platforms for transformation, governance, and visualization. Solutions like ETL platforms can range from tens to hundreds of thousands of dollars annually.
- Personnel and training: Hiring, onboarding, and developing data engineers and analysts quickly becomes one of the largest cost drivers. Recruitment and onboarding alone can run into several thousand dollars, while ongoing salaries represent a significant long-term investment. For example, entry-level data analysts typically earn between $63,000 and $100,000 per year, according to Glassdoor.
- Data integration and maintenance: This covers the ongoing work needed to cleanse or transform data pipelines. Higher service-level agreements can add costs ranging from a few hundred dollars to north of $10,000 per month.
- Contingency and risk mitigation: This provides a reserve fund to address unforeseen expenses or risks during the initiative. Contingency budgets can easily account for 10-20% of a total budget.
Proactive budgeting allows leaders to outline how a data initiative aligns with broader business goals. It also encourages a cost-conscious culture within data teams. These steps boost the fidelity of cost monitoring and ensure that each line item connects to tangible, measurable outcomes.
3 initial steps for adopting an enterprise data governance mindset
As data validation evolves, savvy leaders must adopt an "enterprise-first" governance mindset to rally support from key stakeholders.
1. Position enterprise data governance initiatives as an ongoing practice
Enterprise data governance must function as a continuous improvement cycle rather than a periodic compliance check. Teams should establish regular review cadences and track operational metrics like data quality scores and access rates.
2. Embrace federated governance and cross-team accountability
Leaders should adopt models that support domain-level accountability. This involves encouraging collaboration across data teams and ensuring the consistent application of standards, regardless of where the data resides.
3. Diagnose and address key operational gaps
Data leaders should look to DAMA-DMBOK as a foundational reference for management and governance efforts. It helps identify missing components and align governance processes at an enterprise's scale. Using these standards helps bridge the gap between best practices and operational reality.
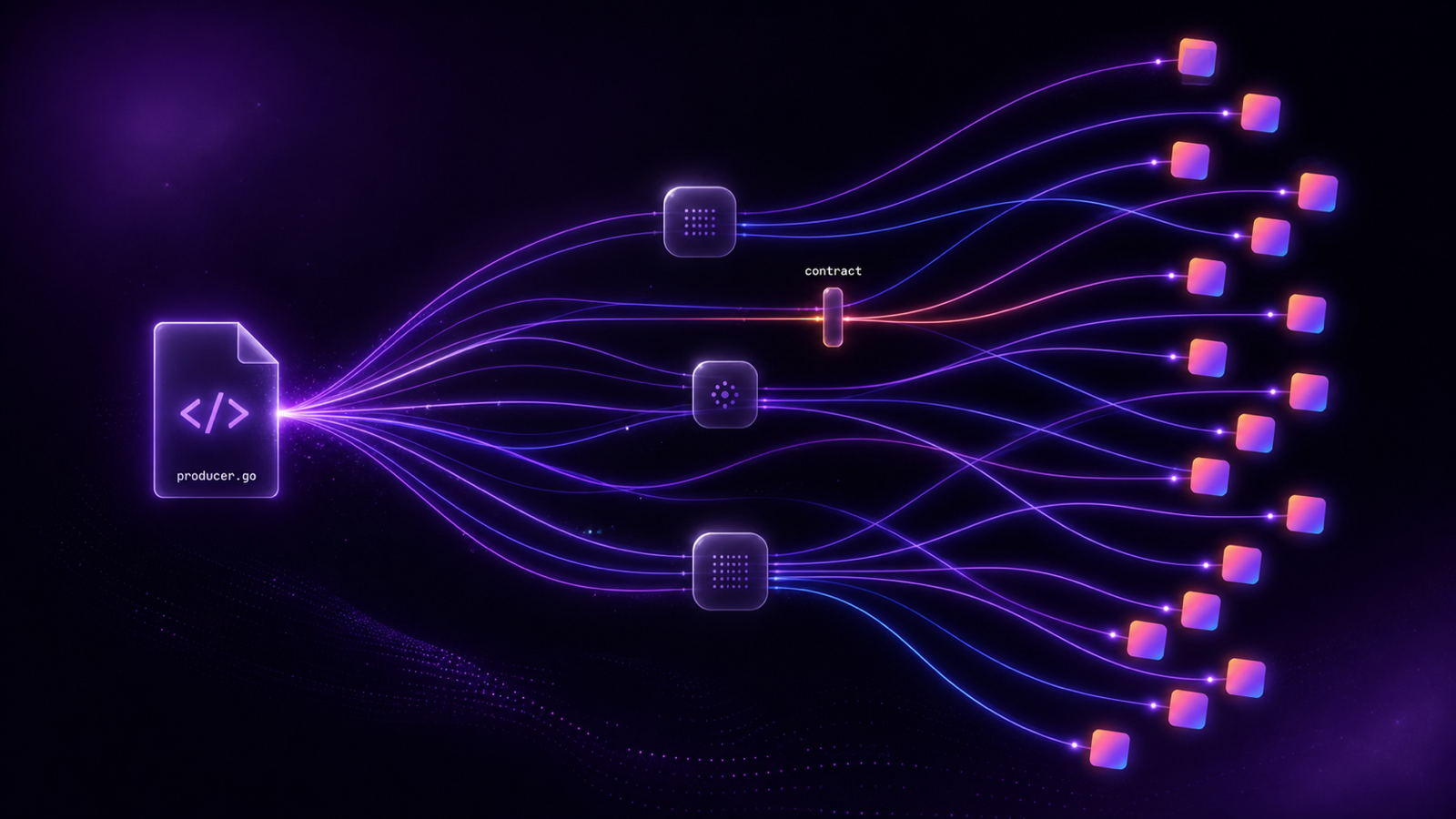
Shifting left: The role of data contracts in validation
A sustainable approach to quality requires a shift to proactive validation. This means enforcing data expectations before information enters critical pipelines.

The transition depends on two fundamental pillars:
- A shared definition of what “valid” means
- Mechanisms that automatically enforce those standards
Establishing a shared understanding
Stakeholders must agree on what constitutes valid data for specific use cases. This shift moves quality from an implicit assumption to an explicit, documented data contract. A data contract defines the schema, the semantics, and the expectations of the data. Without this agreement, teams default to local control, which leads to shadow approaches to data sharing and access.
Codifying enforceable expectations
Shared understanding must be codified into automated checks enforced at the point of data creation in application code. These expectations should be embedded directly into data pipelines using robust validation frameworks.
Any data failing these checks must be quarantined or rejected to prevent corruption from propagating downstream. Enforcement starts at the first mile, before data enters the pipeline.
Revolutionizing data validation with Gable
Effective validation strategies start at the source and remain visible across teams. They’re automatically enforced and version-controlled. This is where Gable provides a unique advantage by moving data quality upstream into the software development process.
Gable is a shift-left data platform that implements data contracts at the application code level. Unlike traditional tools that detect problems downstream, Gable works directly in the software engineering workflow to catch breaking changes before code is committed.
This shift changes how validation works in practice:
- Upstream data contracts: These allow developers to define and enforce schemas and validation rules directly in their application code.
- Code-level lineage: This automatically maps data lineage from application code through the entire pipeline.
- Predictive change detection: This identifies breaking changes before they are deployed, preventing data outages.
- Integration testing for data: This provides automated contract management and versioning to ensure data compatibility.
By bridging the gap between software engineers and data teams, Gable helps organizations stop firefighting and start preventing data quality issues at the source. This proactive approach builds organizational trust and allows data teams to remain dedicated to providing strategic value.
To see how shifting validation upstream can protect your downstream systems from breakage, explore Gable's unique approach to code-level contracts.

Gable
April 27, 2026

.avif)
.avif)