.avif)




Data breaches remain a significant risk for many companies. Over the past decade, the number of data breaches has increased more than four times, with nearly 95% driven by financial motives. In today's environment, stronger protections for sensitive data are no longer optional—they're a baseline requirement.
Relying solely on firewalls or periodic security scans isn’t enough. As data is increasingly treated as a product and managed through code, the logical next step is enforcing security through code itself.
This means embedding security controls directly into the data lifecycle. By enabling data scanning and sensitive data masking upstream, then applying those controls consistently during ingestion and transformation, organizations can reduce exposure early, limit downstream risk, and enforce security across reliable data systems.
This guide explains how data scanning works, which tools support it, and how you can deploy scanning and masking upstream to secure data from the ingestion phase onward.
What is data scanning?

Data scanning is the process of identifying and analyzing sensitive data across files, databases, and cloud repositories. It gives organizations visibility into where sensitive data lives so they can apply proper security standards and controls with precision.
In modern data environments, automated tools make this possible at scale. These tools continuously scan data at rest and in transit, classify and index different data types, and validate adherence to established security standards.
Why is data scanning important?
IBM's 2025 Cost of a Data Breach Report put the average global cost of a data breach at $4.44 million. While that's down 9% from the prior year, the average cost in the U.S. hit a record $10.22 million. Reducing that risk starts with data visibility, and visibility starts with data scanning.
When implemented correctly, data scanning plays a direct role in reducing exposure, enforcing governance, and improving how data is managed across an organization.
Minimizes damage
Data scanning does more than identify sensitive fields. It also uncovers existing points of exposure, such as misconfigured storage, overly permissive access, or unprotected data flows.
Identifying these risks early allows teams to remediate issues before they escalate. When incidents are already in motion, early detection limits downstream impact and reduces overall damage.
Enforces compliance
Continuous scanning detects changes in data structure, content, and location as they occur. These signals enable automated notifications to data owners and administrators, triggering real-time updates to protection rules and access controls.
As data evolves, governance policies evolve with it, ensuring ongoing alignment with regulatory requirements and internal standards.
Facilitates data classification
Data classification groups information based on sensitivity and risk. Scanning provides the foundation by identifying data types, applying tags, and attaching relevant metadata.
With accurate classification in place, teams can apply the appropriate security controls to each category, making sensitive data easier to protect and less costly to manage.
Enables indexing and retrieval
Data scanning analyzes schemas, fields, metadata, formats, and relationships across data sources for accurate and efficient indexing.
This structured metadata and mapping improves search precision and retrieval speed, allowing users to access required data faster without unnecessary exposure.
How data scanning works
Data scanning works by systematically reviewing data sources to understand what data exists, how it is structured, and what it contains.
The process begins with identifying and connecting to data sources such as files, databases, applications, and storage systems. Once connected, the scanner analyzes schemas, fields, formats, and basic patterns to establish an initial understanding.
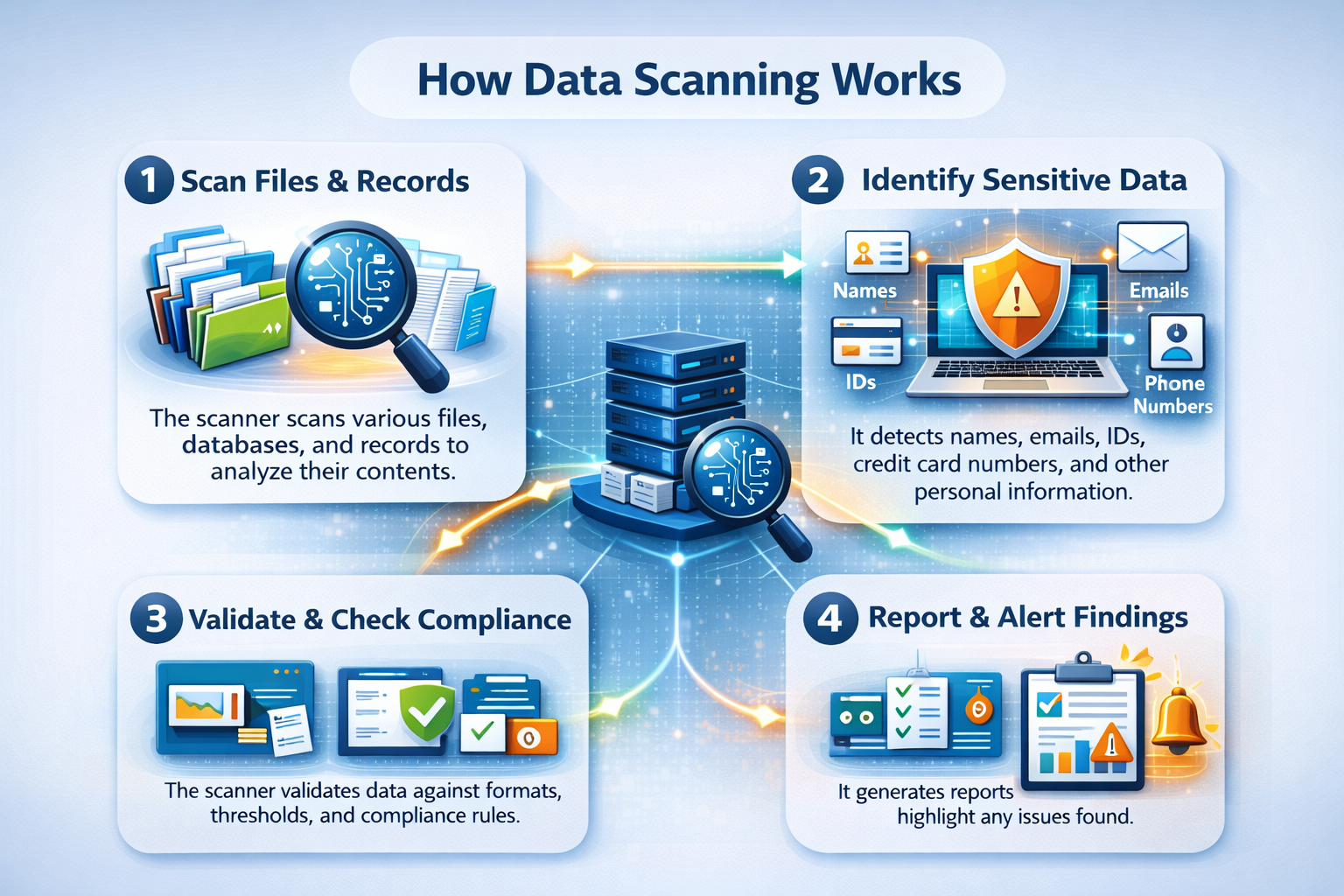
1. Identify and classify sensitive data
As files and records are read, the scanner looks for patterns that indicate sensitive information. It searches for identifiers like names, email addresses, phone numbers, government IDs, credit card numbers, and other forms of personally identifiable information. Pattern matching, rule-based detection, and classification logic work together to surface potential exposures early.
2. Apply context and validation rules
The scanner then applies contextual rules to interpret these findings. Quality checks verify that values fall within expected ranges, while validation rules confirm formats and relationships. The scanner also applies compliance rules to flag personal or regulated data and uses threshold-based outlier detection to help distinguish healthy records from those that need attention.
3. Assess access, exposure, and risk
At the same time, the scanner evaluates the context around that data, including who has access to it, how it is protected, and whether it is encrypted. By combining content analysis with access evaluation, the system highlights high-risk locations where personal data may be overexposed, poorly secured, or stored longer than necessary. It then helps teams determine whether current controls meet regulatory requirements and internal security policies, turning raw discovery into actionable insight.
4. Track lineage and enforce data contracts
Track lineage alongside scanning. Many scanning tools stop at the data they inspect, but pairing scanning with lineage tracking makes the results more useful. Lineage records what actually happens as data moves through pipelines, queries, and transformations, giving teams an end-to-end view of where sensitive data originates, how it's transformed, and where it ends up.
Data scanning further enables enforcement of data contracts that define expectations such as required fields, data types, nullability, update frequency, and downstream usage constraints. Scanners continuously compare these expectations against production reality, and if a column is removed, a type changes, or unexpected sensitive data appears, validation fails immediately. This ensures datasets remain trustworthy, compliant, and fit for use as they evolve.
Top 5 data scanning tools
Data scanning tools vary widely in how they detect, classify, and protect sensitive data. Some focus on cloud storage, others integrate directly with data pipelines, and still others operate at the code or policy level.
The right choice depends on factors such as where your data lives, how it moves, and the level of automation and control your organization needs. The list below highlights leading tools, what each does best, and where it fits.
1. Google Cloud DLP
Google Cloud Data Loss Prevention (DLP) is part of Google’s Sensitive Data Protection suite. It is designed to identify, classify, and protect sensitive information—such as financial data and personally identifiable information—across Google Cloud storage and applications.
The service includes a data discovery capability that uses metadata and contextual signals to surface high-risk data. Its inspection engine allows teams to define what counts as sensitive data, then performs deep scans to detect it at scale. Google Cloud DLP also supports data de-identification techniques, including masking and tokenization, enabling safe data use without exposure.
Cloud DLP is available via API, allowing organizations to embed sensitive data detection and protection into pipelines and governance workflows programmatically. It is best suited for teams operating primarily within the Google Cloud ecosystem.
2. AWS Macie
Amazon Macie uses machine learning technology to discover, classify, and protect sensitive data stored in Amazon S3. It continuously evaluates bucket contents and access patterns to identify confidential data, policy violations, and potential security risks.
Macie also monitors access controls and activity to help teams detect misconfigurations and unexpected exposure. Through integration with AWS Security Hub, it provides centralized visibility into data security findings and overall compliance posture. These insights support regulatory requirements such as GDPR and HIPAA while enabling automated risk assessment across S3 environments.
3. Microsoft Presidio
Microsoft Presidio is an open-source framework for detecting, masking, and protecting sensitive data (PII) across text, images, and structured data. It uses a combination of NLP and pattern-matching methodologies to make this possible.
Presidio is composed of modular components: The Presidio Analyzer identifies sensitive entities in text, the Presidio Anonymizer applies masking and de-identification techniques to protect exposed data, and the Presidio Image Redactor extends protection to images using optical character recognition and entity detection.
Presidio is available as an open-source Python SDK. Teams can embed it directly into applications as a Python library, run it as a containerized REST service, or integrate it into data pipelines using tools like PySpark within Microsoft Fabric or similar platforms.
4. BigID
BigID is an enterprise data privacy and protection platform built to discover, classify, and govern sensitive data across cloud and on-premises environments. It automatically categorizes data based on sensitivity, helping organizations maintain consistent protection and regulatory alignment.
The platform offers data mapping and lineage capabilities that track how data moves across systems. This visibility helps security teams identify potential risk points, understand relationships between datasets, and surface compliance gaps as data flows through the organization. Using this context, BigID enforces necessary access controls and compliance with data protection regulations such as GDPR and CCPA.
5. Gable AI
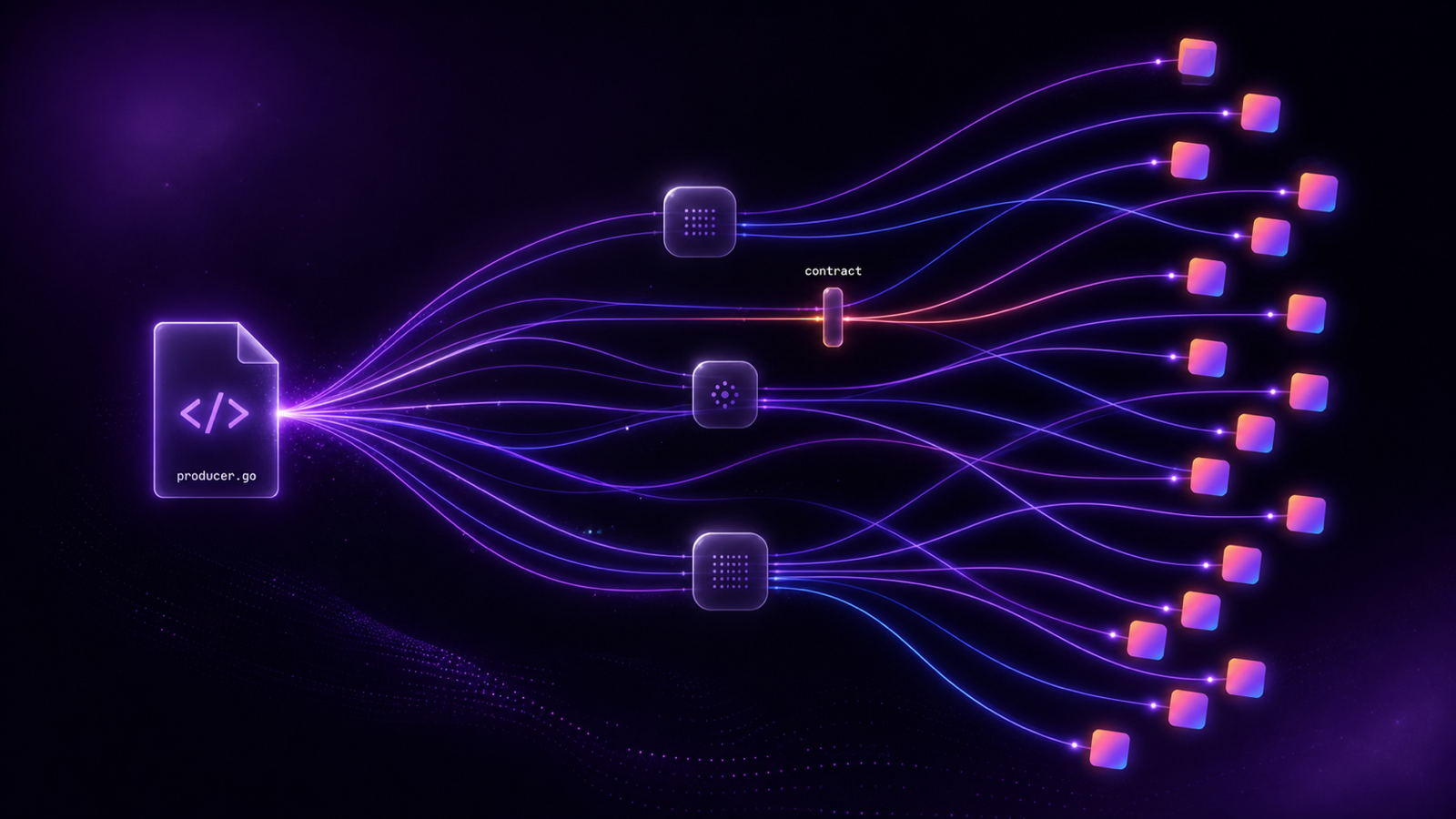
Gable approaches the problem from the opposite end of the stack. Rather than scanning data once it's landed in storage, Gable uses static analysis of your application code to trace where sensitive fields originate, how they're transformed, and where they end up before any data is produced.
That makes it complementary to the content-scanning tools above: scanners answer 'what sensitive data is in this bucket today?', and Gable answers 'which code paths put it there, and what happens if we change them?
Gable's scanning engine examines SQL, transformation logic, orchestration workflows, and metadata across the stack, providing data visibility into assets, schemas, and pipeline flow while automatically building a centralized source of truth.
While Gable's primary enforcement mechanism is data contracts, its static code analysis and CI/CD contract checks also support data governance. Contracts can enforce schema-level expectations like required fields, types, nullability, value ranges, and Gable's code-level lineage shows exactly where sensitive fields originate and how they propagate, so teams can prevent unsafe changes before they ship.
Ensuring the security of sensitive data
Data scanning plays a critical role for organizations handling sensitive information. It provides visibility into where private information resides, helping teams detect issues early and reduce the impact of potential breaches.
Many data scanning tools focus on detecting sensitive data only after it has been stored or processed, leaving upstream risks unaddressed. As a code-first tool, Gable supports a shift to earlier enforcement by scanning the logic behind ingestion, transformation, and pipeline steps. By enforcing security and governance through data contracts, it helps prevent sensitive data from reaching downstream systems and strengthens your overall security posture as you scale.
See how a code-first approach can protect sensitive data from the start—request a demo to explore Gable in action.

Gable
May 4, 2026

.avif)
.avif)