.avif)




Most organizations audit data the same way they always have: they review reports, sample tables, or run checks after something looks wrong. That approach worked when data lived in a handful of systems and changed slowly, but it doesn’t work anymore because modern data pipelines are distributed, event-driven, and constantly changing.

Today, application code creates data, services transform it, and dozens of downstream systems reuse it. As a result, when issues surface late, you’ll end up running reactive investigations that take days, not minutes. Improving outcomes here depends on auditing the systems that create and change data rather than repeating downstream checks. That’s why it’s time to shift visibility upstream and automate audits to the layers that produce and change your data.
What is a data audit?
A data audit systematically evaluates how systems create, transform, and consume an organization’s data. At its core, the audit process answers these three questions:
- “Where does data come from, and which data sources produce it?”
- “How does it change?”
- “Does it behave as teams expect it to as it moves through data processing systems?”
Traditionally, data audits focus on static assets and surface-level data accuracy. During them, teams review warehouse tables, validate reports, or check dashboards for accuracy and completeness. And while these checks are useful, they only show what data looks like at rest. They don’t explain how the data arrived there, what assumptions shaped critical data along the way, or which change introduced a problem.
Modern data systems operate differently, though. With them, data originates in application services before moving through events, pipelines, and transformations into analytics, machine learning, and operational tools. So in this environment, auditing data means auditing how specific data flows through systems, not just outputs. This process requires visibility into the following aspects of how data behaves across the system:
- Data moves through services and software components.
- Transformations alter structure and meaning.
- Changes propagate across the system.
A modern data audit is therefore not just a one-time review but a core part of data governance, an ongoing process that supports data integrity, traceability, accountability, and confidence as systems evolve.
Why data audits matter today
Data audits matter today because the cost of getting them wrong has increased for both teams and stakeholders. And at the same time, traditional approaches’ effectiveness has declined.
The issue here, however, isn’t that teams care less about data quality. Instead, it’s that the systems that produce data have evolved more quickly than the audits your teams rely on to govern them have.
Here’s why this change is so important to understand:
Late discovery is now the norm
Teams often uncover data issues only after the fact. That’s because these issues surface later, often when someone notices a broken dashboard or an unexpected metric that affects business decisions.
According to Datachecks' 2024 State of Data Quality report, 72% of data quality issues are only discovered after they've already affected a business decision. So by the time a problem is visible, it's already shaped a downstream outcome.
This pattern reflects how teams typically apply audits today. Most audits concentrate on downstream outputs like warehouse tables, reports, or dashboards. As a result, teams often miss earlier signals—such as schema changes or shifts in data semantics that application code introduced—and encounter issues only after data has propagated through the system.
That timing matters because it shapes both detection and response. When audits surface issues only at the point of consumption, teams lose the opportunity to catch breaking changes closer to their source, where fixes take less time and create less disruption.
Late discovery increases resolution time and cost
When you detect data issues late, resolving them is often slower and more expensive. That’s because you have to trace the problem backward through multiple services, pipelines, and transformations to identify the root cause.
This dynamic shows up clearly in industry research. Monte Carlo's 2024 State of Reliable AI survey found that 70% of data leaders say it takes longer than four hours to identify a data incident once it occurs, but in complex systems, those hours often turn into days of cross-team coordination.
Datachecks’ report supports this finding by showing that data teams spend a whopping 40% of their working hours solving problems rather than creating value. That means that, instead of improving products or enabling insights, teams are spending huge amounts of time reconstructing issues.
Data failures now carry direct financial risk
Data issues are no longer isolated technical inconveniences but a source of potential risks that carry measurable financial consequences. In fact, Monte Carlo also found that two-thirds of organizations have experienced a data issue with a $100,000 impact in the past six months. These costs include operational disruption, delayed decisions, and downstream remediation work.
When audits fail to catch issues early, small changes become expensive incidents because downstream audits only surface problems after data has already propagated through multiple systems. What’s worse, though, is that in regulated environments, that same delay can also create data compliance gaps, which make it harder to explain what changed, when it changed, and who was responsible.
Reactive monitoring doesn’t work in distributed systems
Modern architectures amplify the risk of late discovery and reactive investigation because data pipelines now span microservices, real-time streams, and multi-cloud environments. In this context, manual checks and periodic audits can’t keep pace.
Additionally, 2024 research in the International Journal of Advanced Multidisciplinary Research and Studies concludes that traditional, reactive approaches to data monitoring don’t cut it anymore. The paper states that “in this fragmented and high-velocity environment, the traditional, reactive approaches to data monitoring are no longer sufficient. [...] Organizations can no longer rely solely on ad hoc checks or manual inspection to identify data quality issues that may propagate downstream and impact decision-making, compliance, or operational performance.” In other words, as data moves across services and pipelines, periodic audits lose the ability to surface problems before they spread.
But these limitations also extend beyond tooling, pointing to a structural issue in audit methodology. This means that approaches for static systems don’t have the right structure to operate in dynamic, distributed data flows.
How to audit data flows through services and software systems
Nowadays, to audit data effectively, you need to shift your focus from isolated assets to the systems that create and move data. Here’s how modern audits follow data through those systems:
Tracing data from source to sink
Audits often focus on downstream outputs, which leads you to treat the data warehouse as the starting point. In practice, however, data rarely originates there. Instead, it originates in application code, where services emit events, APIs expose fields, and pipelines reshape data long before it reaches an analytics layer.
As a result, audits that stop at the final table miss critical context because they can’t show which assumptions started upstream, how those assumptions changed over time, or which specific change altered the data’s meaning as it moved through the system. That context is important since most data issues start at the point of creation or transformation, not later on at the point of consumption.
A modern audit, therefore, needs to trace data from its point of creation through every transformation and dependency until it reaches consumption. This is what makes it possible to connect downstream impact back to the systems and changes that caused it.
Mapping the transformation chain
Effective audits shouldn’t examine data as a single static asset. Instead, they examine how responsibility and risk shift as data moves through the system.
In practice, this means looking at these key participants in the data lifecycle and understanding how each one shapes data in different ways:
- Data producers define the initial structure and meaning of data at the point of creation. So when a service changes a field type, renames an attribute, or stops emitting a value altogether, that change immediately affects how downstream systems interpret the data. These decisions can thus introduce risk early, long before the data reaches a warehouse or report.
- Data transformations then reshape that data as it moves through pipelines. But these joins, aggregations, and enrichment logic don’t just reorganize fields. They can also subtly change semantics by altering granularity, combining sources with different assumptions, or applying business logic that downstream checks may not fully capture.
- Data consumers like dashboards, models, and applications then reveal where those changes ultimately matter by surfacing the impact of upstream decisions on metrics, decisions, and operations. However, waiting to detect issues at this stage means you’ll already be too late. By the time consumers expose a problem, the data has propagated across systems, increasing both the scope of impact and the effort that’s necessary to resolve it.
Auditing across all three roles provides the context you need to understand where a change originated, how it evolved, and why it produced downstream impact. That visibility shortens investigation time, clarifies ownership, and makes it possible to address issues closer to their source rather than reacting at the point of failure.
Tracking lineage through change
In distributed systems, change is constant, which makes it difficult to understand how data behaved at any given moment without a record of what changed and when. As a result, audits will then turn into forensic exercises that teams can only conduct after the fact.
Automated lineage provides that missing context by creating evidence across systems and formats to show how data moved, which services touched it, and which downstream assets depend on it. Change tracking then adds temporal context so teams can connect incidents to specific deployments or schema updates. Together, these features turn audits from guesswork into analysis.
Defining ownership and accountability
Audits that identify issues without identifying ownership rarely lead to resolution because teams lack a clear path to act on their findings. And when responsibility is unclear, issues will stall between services and teams, even when they understand the underlying problem well.
This challenge becomes more pronounced in distributed systems, where data flows across many services and organizational boundaries. For instance, changes that come into play in one service often affect the downstream systems that different teams own, which makes it difficult to determine who’s responsible for investigating, fixing, and validating a change.
Modern data audits address this gap by making ownership explicit in addition to surfacing what changed. That means showing which team owns the change, where it originated, and which downstream assets it affects. This clarity shortens resolution time, reduces coordination overhead, and creates a defensible record of responsibility that supports regulatory expectations.
5 best practices for modern data auditing
Modern data auditing is less about checklists and more about embedding visibility into how systems operate. The following practices outline how you can build audits that flag issues early, scale with change, and reduce reactive work:
1. Treat audits as continuous, not periodic
Periodic audits assume stability, yet modern systems change every time code changes. That mismatch creates blind spots between reviews.
However, continuous auditing closes that gap by allowing visibility to evolve with the system and monitoring behavior as it happens rather than sampling outputs after the fact.
2. Move audit checks upstream
Downstream audits only show you what’s already broken, but upstream audits show you what’s about to break. By watching data creation and transformation closely, you can catch issues before they ripple through the system.
Teams that improve data quality usually start at the source by defining what data should look like as it enters the system and enforcing those expectations as part of normal development and deployment. That approach reduces cleanup work later and keeps small changes from turning into widespread failures.
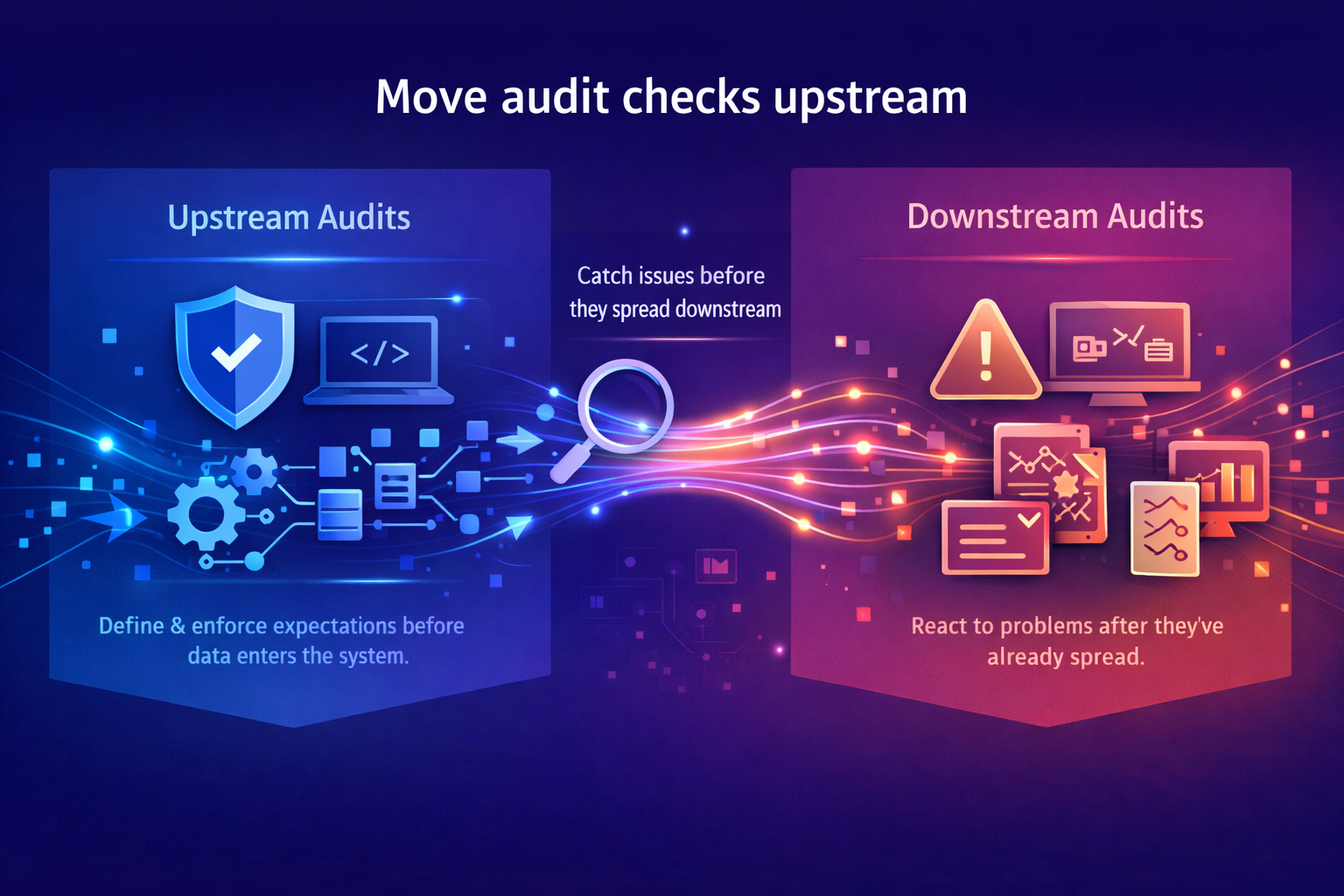
By auditing upstream in this way, you can protect the decisions that depend on that data. As a result, issues surface earlier, fewer systems feel the impact, and you’ll spend less time reacting to problems.
3. Audit expectations, not just outcomes
If no one defines what “correct” means from the outset, data can look right even after something important has changed beneath it. To avoid this issue, teams need to set clear expectations early by spelling out what data should contain, what it represents, and how downstream systems depend on it.
When teams define those expectations upfront, they can use modern audits to catch incompatible changes as they happen instead of reacting after the fact.
4. Automate evidence collection
Manual audits don’t scale in fast-moving systems or support the timeliness of data collection. But when you automate evidence collection as part of normal development and deployment workflows, audits become a by-product of how the system already operates, which helps audit teams streamline their work.
Automation also creates consistent, defensible audit trails—such as schema diffs, lineage graphs, and contract validations—without adding operational overhead. These artifacts provide a reliable record of what changed, when it changed, and how that change affected downstream systems. As a result, you can respond to incidents faster, demonstrate compliance with less manual effort, and support reviews with evidence that already exists instead of documentation that you assemble after the fact.
5. Make audits legible to the business
Audits shouldn’t live solely in technical dashboards. To drive action, teams instead need to translate technical findings into language that business leaders understand and care about. For example, instead of only reporting that a schema changed in a service, an audit should show how that change affects a revenue report, customer metric, or another decision that the business relies on.
When leaders can clearly see that connection, audits stop feeling like a compliance exercise and start acting as tools that support more informed decisions and data-driven initiatives.
Rethinking data audits for modern systems
Data audits need to evolve because the systems they govern have changed. In modern architectures, data originates in application code and moves through services and pipelines long before it appears in a report. As a result, audits that focus only on downstream outputs miss where changes actually begin.
Modern audits instead support ongoing risk assessment by maintaining continuous visibility into how data flows and evolves across systems. Additionally, shifting left to audit upstream helps teams detect breaking changes earlier and understand their downstream impact, which reduces reactive work.
This is where Gable comes in. Gable uses static analysis of your source code to trace field-level data lineage from consumer apps through backend systems and storage — no runtime agents, no sampling, no production overhead — and ties each release to its inputs and transformations as part of normal CI/CD workflows.
If you want to understand how this works in practice, try the demo today to learn how code-level visibility changes the audit experience.

Gable
May 4, 2026

.avif)
.avif)