.avif)




If you were coding back in the 90s, you probably remember how the software development process used to run. Most teams followed the Waterfall model, a linear and sequential process that involved analysis, design, implementation, testing, and maintenance.
But this process leaves no room for flexibility. It can’t accommodate mid-project changes or speed up the cycle since every stage depends on the one before it. You simply have to wait for the previous stage to finish before moving ahead.
Then came the Agile approach, which ended this rigid workflow. Shift-left testing within Agile focuses on bringing testing and QA earlier into the software development lifecycle (SDLC). Many data teams are now doing something similar: moving data quality, governance, and contract enforcement to the ingestion stage. This shift means fewer surprises downstream and more reliable data pipelines for engineers and consumers alike.
Let’s take a closer look at what shift-left testing really means, how it works, and how to implement it.
What is shift-left testing?
Shift-left testing moves testing earlier in the software development process, into the design and development phases. That way, instead of waiting for development to finish before testing functionality or data logic, you can run both in a continuous loop, validating code as you write it and fixing issues right away.
Now, as data pipelines become more complex, data engineers face the same challenges software engineers once did: schema changes, lineage breaks, and dependency errors that break downstream applications that consume this data. To catch and fix these issues early, teams can apply the same shift-left mindset to data. This involves validating the schema and implementing data contracts as soon as the pipeline generates the data.
The benefits of shift-left testing
When teams understand why shift-left testing matters, they’re better equipped to handle the challenges that come with putting it into practice.
Here are some of the benefits of shift-left testing:
- Proactive approach: Shifting left changes testing from a reactive process to a proactive one. This means that instead of cleaning up broken pipelines or fixing bad data after deployment, you can use this proactive approach to prevent issues by validating data quality, schemas, and contracts early in data ingestion.
- Faster release cycles: Shifting testing left also shortens the feedback loops between development and testing. In CI/CD, tests run alongside code commits and provide immediate feedback on functionality, allowing developers to resolve issues right away without waiting for full development to finish. This parallel process speeds up the SDLC and enables faster time-to-market for new features.
- More secure product/data: Testing is a living process, not a single phase. As part of continuous integration, each code push triggers automated quality and security tests, and the build only passes when all checks succeed. That means even a small change will go through comprehensive testing before reaching production.
- Greater data quality: When teams detect and fix data issues at the ingestion stage, they’ll prevent problems from reaching downstream applications. This proactive approach provides accurate, up-to-date, and stable data for data consumers.
- Enhanced collaboration: By validating data quality and contracts early in the pipeline, teams will gain shared visibility into schema changes and potential impacts. Producers define data assets and contracts from the very beginning, while consumers access expectations and dependencies. This upfront collaboration keeps both teams aligned and improves transparency across the entire data flow.
Types of shift-left testing
The shift-left mindset can look different depending on whether you’re testing code, data, or both. Understanding the various types of shift-left testing helps teams choose the right strategy or combine multiple methods effectively.
Traditional shift-left testing
Traditional shift-left testing focuses on testing code logic and functionality during the build itself. By involving testers during design and development, teams can define testing goals, plan coverage, and catch issues earlier.
This early testing centers on API, unit, and integration tests that validate each component independently before combining them into the larger system.
Incremental shift-left testing
During large, complex projects, teams often break development into small deliverables or modules and build them incrementally. Each of these modules will have its own design, build, and test cycle, which means every time the team develops a new module, they’ll immediately run unit and integration tests on it.
After completing all modules, the team will move the full project into operational and acceptance testing to validate its performance as a whole.
When teams apply this incremental approach to data, they test data models, ingestion layers, and transformation components as they develop them. That way, each module validates its own data inputs, outputs, and quality rules before connecting to the next stage.
Agile and DevOps shift-left testing
Teams apply an Agile approach once the software is operational. During this stage, they’ll add new features, fix bugs, and improve performance in each sprint. The Agile shift-left testing ensures all those updates go through continuous testing before release. That means every code commit triggers existing automated tests (such as unit, integration, or regression testing) as part of CI/CD.
The same DevOps shift-left principles extend to data. Teams treat data as code, embedding governance policies and quality checks directly into the pipelines that produce it. They define standards such as personally identifiable information (PII) tagging, schema validation, and retention rules, which are then automatically enforced whenever upstream data changes.
Model-based shift-left testing
A model-based shift-left strategy moves testing to the requirements and design phases. This involves testing product requirements and design before developers write any code.
At this point of the SDLC, test architects or designers create visual representations that show how the product should behave. UML diagrams, flowcharts, or sequence diagrams help them capture this logic. They then use model-based testing tools to analyze these models. These tools highlight problems like missing states, unreachable paths, or undefined conditions in the requirements.
After refining and approving the model, the tools automatically generate test cases from the finalized design model. Teams can save these tests to run later when they develop the corresponding components.
How to implement shift-left testing
To successfully implement a shift-left testing approach, teams should follow a structured process that fosters team collaboration and leverages available resources.
While specific processes will vary depending on your project’s needs, the following steps outline a practical framework to help you get started:
1. Test during the design phase
When teams plan testing strategies and contracts early, they can identify risks, dependencies, and failure points before they affect downstream systems. Achieving that level of foresight requires collaboration between developers, testers, and other stakeholders from the start.
By involving testers early, teams can align on testing goals, clarify assumptions, and ensure the test plan reflects real project requirements. This collaboration also gives testers the full context of project goals and requirements, allowing them to anticipate edge cases, spot potential gaps, and design more effective test scenarios.
The same principle applies to shift-left data. Data engineers, developers, and analysts define what good data looks like by setting validation rules, schema requirements, and governance standards. Aligning on these principles upfront prevents late-stage issues and ensures consistent quality downstream.
2. Set up static code analysis
Static code analysis tools scan source code without running it and flag potential bugs or code quality issues right inside your IDE. They help engineers catch issues early, before the code is ever executed, saving time on debugging and reducing the risk of defects slipping into production.
Other tools, such as static application security testing features, go a step further by identifying security vulnerabilities in the source code during development. This makes them crucial for maintaining code reliability and protecting against potential breaches.
For data pipelines, static data analysis tools can scan SQL models, transformation scripts, and schema definitions to detect potential errors before execution. Catching these issues upfront helps teams avoid broken transformations, failed jobs, and downstream data quality problems, ensuring production data stays consistent and trustworthy.
3. Use mocking and service virtualization
If another team is still developing the component that your code relies on, you can still test it using mocking or service virtualization.
You’d use mocking when you’re missing just one component, like a database, API, or user interface. The mocking tool’s interface or configuration files let you create mock endpoints and define responses based on expected contracts. These endpoints act as stand-ins for the missing component so you can continue testing without delays. Tools like WireMock and Mockaroo are commonly used for this. They simulate responses from APIs or data sources to help teams validate functionality early.
If the entire backend service isn’t ready yet, you’d use service virtualization. This tool creates a simulated backend service that mimics the real one. You can then run developed components within these simulated production environments and test their functionality. Popular tools such as Broadcom Service Virtualization help teams create these simulated services to test complex systems before all components are live.
In data workflows, this approach also applies to upstream datasets. Teams can generate mock data that follows the same schema and validation rules defined in their data contracts to simulate pipeline steps that are still under development. This mock data replaces unfinished components, allowing teams to test pipelines end-to-end before full development.
4. Build CI pipelines
Continuous integration (CI) pipelines automatically run tests whenever teams push new code or data changes. This setup lets teams test changes continuously throughout development.
To enable this, teams typically integrate a CI tool such as GitHub Actions, GitLab CI/CD, CircleCI, or Jenkins. These tools connect directly to your repository and trigger automated tests whenever changes occur.
Within your repository, you’ll also need a configuration file that defines what gets tested and when. For instance, when using GitHub Actions, this might be a file named “.github/workflows/test.yml.” Inside that file, you can specify which test scripts run on which branches and under what conditions. GitHub Actions then follows these rules automatically and runs the tests every time developers commit code or modify data models.
5. Set up monitoring and reporting
Dashboards, tests logs, and real-time alerts give teams visibility into software performance. These insights highlight weaknesses in current testing processes and gaps in code coverage.
In a shift-left data approach, teams continuously observe data quality metrics, contract compliance, and transformation accuracy. Then, when an issue surfaces, such as a failed validation or a broken dependency, the system alerts teams immediately so they can address the issue before it affects downstream consumers.
Shift-left testing best practices
To effectively shift left in data-driven environments, teams and leaders should embrace the following best practices:
Enforce test-driven development
Test-driven development (TDD) helps teams build high-quality code or data products faster by catching issues early. The approach flips the traditional order of operations: instead of writing code first and testing later, teams write tests first to define the expected behavior of their applications.
By involving testers early in the requirements phase, teams can create the tests upfront. Developers then write code that meets those expectations, ensuring each feature satisfies its intended purpose.
This avoids the rework involved in the traditional approach of writing code first, then creating tests, running them, and fixing the issues that cause failures.
Similarly, when building data pipelines, teams should create contract-driven tests that define what valid data should look like before building the pipelines that produce it. These data contracts establish clear expectations around schema, field types, naming conventions, and business logic. Developers and data engineers can then write transformations that comply with those rules.
Embrace security automation
The earlier teams scan and fix security issues, the less likely those issues will make it into production. That’s why the shift-left testing approach scans for security issues more frequently and earlier in the development cycle.
In shift-left data, the same principle applies. Automated checks validate data access controls and PII handling throughout the CI/CD process, ensuring data remains secure and compliant before it reaches downstream systems.
Code coverage
Tracking code coverage helps teams understand how thoroughly their codebase is tested and where gaps remain. By integrating coverage reports into early testing frameworks, teams can clearly see which parts of the code have been tested and which haven’t.
The same idea applies to data workflows. Teams can track which datasets, transformations, and pipelines include quality checks and add them where they are missing. This helps validate all data manipulation steps, prevent data quality issues, and build greater trust in production data.
Use AI tools
AI-powered testing tools help teams predict issues faster by learning from past code and data changes. The most effective ones include predictive change-detection features that analyze how code or data updates might introduce new problems.
Unlike traditional frameworks that depend on static rules, AI systems recognize changing patterns in your code and data to forecast where breakages could occur. By using them to catch issues early, teams can adapt quickly and maintain stability as projects evolve.
Expanding a shift-left approach to data products
In today’s AI world, data-driven organizations outperform others, with 58% greater chance of hitting their revenue goals. This proves that your data quality is just as critical as your code quality.
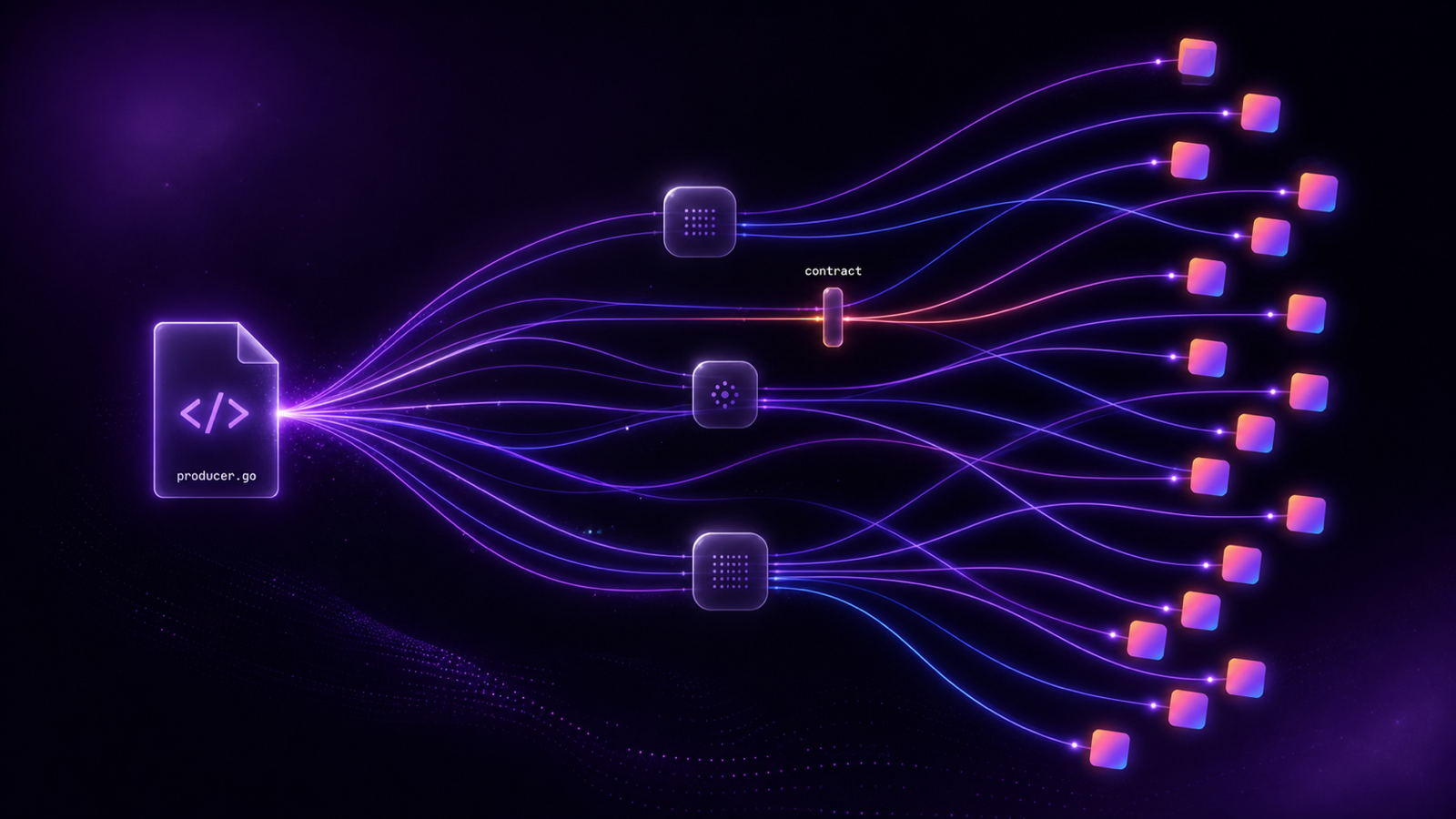
But as data pipelines grow, small schema changes or missing validations can break entire workflows, which is why shifting left is so important. Applying a shift-left approach to data means moving data quality checks, schema validations, and compliance rules to the very start of the data pipeline so you can catch issues early.
Data contracts play a central role in making this possible. They define each data asset’s fields, types, constraints, and ownership so producers and consumers stay aligned from the beginning.
Gable simplifies this process through schema and contract enforcement at the data ingestion stage. It validates data structure at the point of creation, prevents issues before they cascade, and applies DevOps-style governance across the entire data lifecycle.
If your organization wants these same capabilities to maintain high-quality data products, sign up for a Gable’s demo today to see it in action.

Gable
April 27, 2026

.avif)
.avif)